この記事は KMC advent calendar 2021 9日目の記事です。
昨日の記事は Elasticsearch: N-gram tokenizer と N-gram token filter の挙動の違い - Unyablog. でした。今日*1も Elasticsearch の話をします。
本題
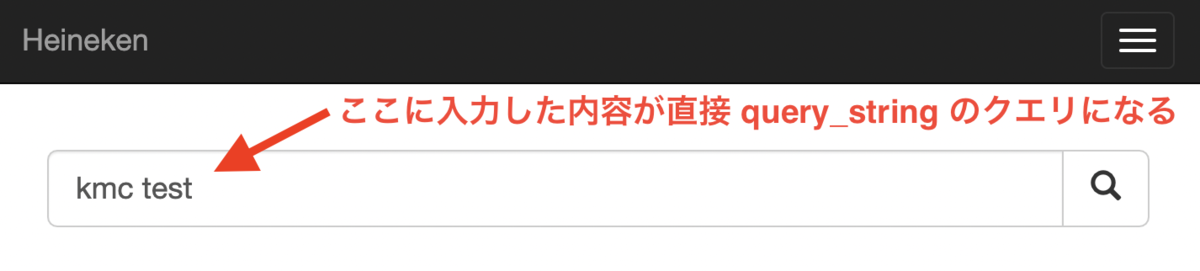
サークル内で開発しているドキュメント検索ツール(Heineken)では Elasticsearch を内部で用いている。
この Elasticsearch を 5.x から 7.x に上げるにあたって、全文検索時に使っていた split_on_whitespace と auto_generate_phrase_queries オプションが使えなくなっていた。使えなくなった経緯と、それに伴う対応のメモ。
split_on_whitespace と auto_generate_phrase_queries とは
どちらも query_string query にあったオプション。
query_string はクエリの処理方法の一種で、与えられたクエリをクエリ言語として一旦パースしてから Search analyzer に投入する。クエリ言語が title:(quick OR brown) といった形式で人間が読み書きしやすいのが特徴で、Heineken でも使っていた。
split_on_whitespace、 auto_generate_phrase_queries はそのクエリ言語の処理時のオプションで、 split_on_whitespace (デフォルトで true)は、パース時にスペース区切りを有効にするもの、auto_generate_phrase_queries (デフォルトで false)は split_on_whitespace で得られたそれぞれの文字列に対して自動的に Phrase query を生成するものだった。
例
kmc test というクエリは、以下のような形で処理されて Analyzer に渡されていた*2。
kmc testkmc AND test(split_on_whitespace=true)"kmc" AND "test"(auto_generate_phrase_queries=true)
この結果、各単語に対して PhraseQuery (match_phrase 相当)が生成されていた。
何が嬉しかったのか
Heineken ではユーザーから受け取った検索クエリを直接 query_string のクエリとして投げていたが、それはこの2つのオプションのおかげで成り立っていた。
auto_generate_phrase_queries
これは Tokenizer として N-gram を使っている場合に必要だった。
N-gram tokenizer を使うと kmc は [km, mc] という Token に分解されるが、ここでもし Phrase 検索を使っていない場合は +body:km +body:mc のような BooleanQuery が生成される*3。これだと km と mc という文字さえ文章中に存在すればヒットするため、 mchoge kmpiyo といった文字列にもヒットしてしまい、 False positive が非常に多くなってしまう。
一方、Phrase 検索を使った場合は body:\"km mc\" という PhraseQuery が生成されるようになる。これは kmc という連続した文字列にしかヒットしないため、思ったとおりの結果を出すことができていた。
split_on_whitespace
これは直感的なスペース区切りの検索を実現するのに必要だった。
上述のように、N-gram では Phrase 検索を行うことが必要不可欠なわけだが、その Phrase 検索は単語ごとに行う必要がある。
もし split_on_whitespace が false だと、 kmc test と入力した場合に "kmc test" という Phrase 検索になってしまう。これだと、kmc test という連続した文字列がないとヒットせず、False negative が多く発生してしまう。この状態でも kmc AND test のように Operator を明示的に書けば別々の単語として投入してくれるが、いちいちユーザーに Operator を書かせるのは大変。
Elasticsearch での両オプションの廃止経緯
…と Heineken では活用していたこのオプションだが、どちらも 6.x, 7.x で廃止された。対応を検討するために、廃止になった経緯を調べてみた。
まず、もともと(5.0 まで)は query_string に split_on_whitespace というオプションはなく、デフォルトで空白文字区切りが有効になっていた。ただ、空白文字で区切られてしまうと不都合な点がいくつかあり、空白文字を含んだ形で Analyzer に渡すべき、という話があったらしい。
... the goal was to ultimately stop splitting on whitespace and let the analyzer do the right thing.
Make `split_on_whitespace` default to `false` · Issue #25470 · elastic/elasticsearch · GitHub
その後、Elasticsearch が内部で用いている Lucene でこの挙動を変更できるようになり、それに応じて Elasticsearch でも split_on_whitespace オプションが 5.1 で導入された。この Issue では "将来的にはデフォルトは false にしたいが今は機能を設定できるようにだけしておく" といった旨のコメントがある。
... we had an agreement that splitOnWhitespace=false should be the default but it would change the expectations for a lot of users so the proposed plan is to expose the feature in 5.x (with default to true) and change the default to false in 6.0.
Expose splitOnWhitespace in `Query String Query` · Issue #20841 · elastic/elasticsearch · GitHub
そして、6.x 以降では両オプションを無視するようにして、7.x では無くすという判断がなされ、実際に Whitespace は Operator としてはみなされなくなった。
Whitespaces and empty queriesedit
Whitespace is not considered an operator.
すなわち、kmc test で AND 検索できていたものを kmc AND test と明示的に書かなければいけなくなった。
auto_generate_phrase_queries に関しては、代替として type というオプションが増えて、クエリからパースされた各文字列がどのように扱われるかを決めれるようになった。例えば type: phrase とすると、内部的には各文字列に対して match_phrase 検索が実行される。
phrase
Runs a match_phrase query on each field and uses the _score from the best field. See phrase and phrase_prefix.
ただ、split_on_whitespace は削除されているため*4、今までのクエリがそのまま使えるわけではない。
Heineken での対応
形態素解析などで Token が意味を残した形で分解される場合は、 Phrase 検索は必須でないため今回の変更はそこまで大きな影響とならないと思われる。
しかし、Heineken は N-gram で Token を生成しているため、今回の変更との相性が悪かった。
前述のように、N-gram では特性上 Phrase 検索できないと False positive が大量に発生してしまうので Phrase 検索は自動でやりたい。そこで type: phrase を設定しても、スペース区切りが廃止されているため kmc test は "kmc test" のようなクエリに解釈されてしまう*5。これでは多くの人にとって意図した検索結果にはならないだろう。
結局 query_string に直接クエリを入れるのを諦め、独自に検索クエリをパースして Elasticsearch に渡すことにした。
まとめ
N-gram を用いて False positive を減らす検索システムを作りたい場合、Phrase 検索を行う必要がある。今までは Elasticsearch の query_string でそれが実現できていた。しかし、split_on_whitespace の廃止によって query_string に直接渡すような実装は相性が悪くなってしまい、 Heineken では独自のパースを行うことになった。
今までありがとう、そしてさようなら、split_on_whitespace と auto_generate_phrase_queries 👋👋
*1:12月27日
*2:なお、この記事では default_operator を AND とした挙動を書いている
*3:ここでは body というフィールドに対して検索をかけている想定
*4:keyword だけは同等の機能が使えるようになっている https://github.com/elastic/elasticsearch/issues/30393 が、今回は text なので使えない
*5:この状態で今までのような Phrase 検索を維持するには Analyzer 内で空白区切りで分解した上で分解した Token に対して Phrase 検索を有効化し、そこに N-gram をかけるといったことが必要になるが、少なくとも Elasticsearch に用意されているものではそのようなことはできない(はず)