この記事は KMC advent calendar 8日目の記事ということにしています。
adventar.org
KMC では部内ドキュメント検索システムで Elasticsearch を使用している 。最近 Elasticsearch のバージョンを上げる準備をしていて、設定の見直しの中で N-gram token filter を使ってみたら想定と違った挙動をしたのでメモ。
Disclaimer
7.16 で確認
検索結果に False positive, False negative がないかの視点で見ている。スコアリング関係は見ていない。
Edge n-gram 、CJK bi-gram については見ていない
エラサーのプロではないので間違っていたら教えて下さい…
TL;DR
N-gram tokenizer はイメージ通り、与えられた文字列を N-gram で各 Token に分解する。各 Token は別々のものになる。N-gram token filter は与えられた Token を N-gram し、新たな Token を登録する。分解された Token は元の Token の情報を引き継ぐので、Token のバリエーションが増えたように(= Synonym)解釈される。
この違いは、インデックス・検索時のパース処理や Highlight 機能に大きく関わってくる。
詳細
前提知識 (Tokenizer と Token filter について)
Elasticsearch では Analyzer でインデックス時や検索時の文字列の処理方法を決める。Analyzer は Char filter, Tokenizer, Token filter で構成される。
www.elastic.co
Tokenizer は Char filter で整形された文字列を受け取って、それを Token に分解する。Token filter は分解された Token を編集したり、追加・削除を行う。
N-gram は Tokenizer も Token filter もある。一体どういう違いがあるのか?
挙動の違い
Analyzer API を用いて kmc test という文字列に Bi-gram を適用し、どのように展開されるかを確認してみる。
Analyzer API 結果詳細(Click to open)
$ curl -X GET "localhost :9200/_analyze?pretty " -H 'Content-Type: application/json' -d '{
"tokenizer ": {
"type ": "ngram ", "min_gram ": 2 , "max_gram ": 2
} ,
"text ": "kmc test ",
"explain ": true
} '
{
"detail " : {
"custom_analyzer " : true ,
"charfilters " : [ ] ,
"tokenizer " : {
"name " : "__anonymous__ngram ",
"tokens " : [
{
"token " : "km ",
"start_offset " : 0 ,
"end_offset " : 2 ,
"type " : "word ",
"position " : 0 ,
"bytes " : "[6b 6d] ",
"positionLength " : 1 ,
"termFrequency " : 1
} ,
{
"token " : "mc ",
"start_offset " : 1 ,
"end_offset " : 3 ,
"type " : "word ",
"position " : 1 ,
"bytes " : "[6d 63] ",
"positionLength " : 1 ,
"termFrequency " : 1
} ,
{
"token " : "c ",
"start_offset " : 2 ,
"end_offset " : 4 ,
"type " : "word ",
"position " : 2 ,
"bytes " : "[63 20] ",
"positionLength " : 1 ,
"termFrequency " : 1
} ,
{
"token " : " t ",
"start_offset " : 3 ,
"end_offset " : 5 ,
"type " : "word ",
"position " : 3 ,
"bytes " : "[20 74] ",
"positionLength " : 1 ,
"termFrequency " : 1
} ,
{
"token " : "te ",
"start_offset " : 4 ,
"end_offset " : 6 ,
"type " : "word ",
"position " : 4 ,
"bytes " : "[74 65] ",
"positionLength " : 1 ,
"termFrequency " : 1
} ,
{
"token " : "es ",
"start_offset " : 5 ,
"end_offset " : 7 ,
"type " : "word ",
"position " : 5 ,
"bytes " : "[65 73] ",
"positionLength " : 1 ,
"termFrequency " : 1
} ,
{
"token " : "st ",
"start_offset " : 6 ,
"end_offset " : 8 ,
"type " : "word ",
"position " : 6 ,
"bytes " : "[73 74] ",
"positionLength " : 1 ,
"termFrequency " : 1
}
]
} ,
"tokenfilters " : [ ]
}
}
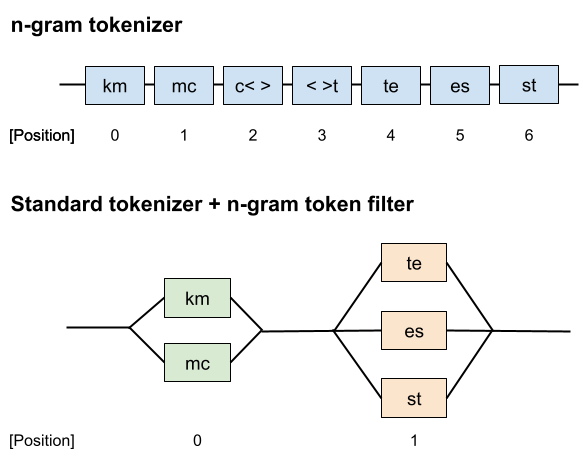
["km", "mc", "c ", " t", "te", "es", "st"] といった Token 列に分解されている。各 Token の位置情報(position や start, end_offset)は Token によって異なっており、全て独立した Token として扱われている事がわかる。
N-gram token filterこの記事では、Tokenizer には Standard tokenizer を使う*1 。
Analyzer API 結果詳細(Click to open)
$ curl -X GET "localhost :9200/_analyze?pretty " -H 'Content-Type: application/json' -d '{
"filter ": [{
"type ": "ngram ", "min_gram ": 2 , "max_gram ": 2
}] ,
"tokenizer ": "standard ",
"text ": "kmc test ",
"explain ": true
} '
{
"detail " : {
"custom_analyzer " : true ,
"charfilters " : [ ] ,
"tokenizer " : {
"name " : "standard ",
"tokens " : [
{
"token " : "kmc ",
"start_offset " : 0 ,
"end_offset " : 3 ,
"type " : "<ALPHANUM> ",
"position " : 0 ,
"bytes " : "[6b 6d 63] ",
"positionLength " : 1 ,
"termFrequency " : 1
} ,
{
"token " : "test ",
"start_offset " : 4 ,
"end_offset " : 8 ,
"type " : "<ALPHANUM> ",
"position " : 1 ,
"bytes " : "[74 65 73 74] ",
"positionLength " : 1 ,
"termFrequency " : 1
}
]
} ,
"tokenfilters " : [
{
"name " : "__anonymous__ngram ",
"tokens " : [
{
"token " : "km ",
"start_offset " : 0 ,
"end_offset " : 3 ,
"type " : "<ALPHANUM> ",
"position " : 0 ,
"bytes " : "[6b 6d] ",
"positionLength " : 1 ,
"termFrequency " : 1
} ,
{
"token " : "mc ",
"start_offset " : 0 ,
"end_offset " : 3 ,
"type " : "<ALPHANUM> ",
"position " : 0 ,
"bytes " : "[6d 63] ",
"positionLength " : 1 ,
"termFrequency " : 1
} ,
{
"token " : "te ",
"start_offset " : 4 ,
"end_offset " : 8 ,
"type " : "<ALPHANUM> ",
"position " : 1 ,
"bytes " : "[74 65] ",
"positionLength " : 1 ,
"termFrequency " : 1
} ,
{
"token " : "es ",
"start_offset " : 4 ,
"end_offset " : 8 ,
"type " : "<ALPHANUM> ",
"position " : 1 ,
"bytes " : "[65 73] ",
"positionLength " : 1 ,
"termFrequency " : 1
} ,
{
"token " : "st ",
"start_offset " : 4 ,
"end_offset " : 8 ,
"type " : "<ALPHANUM> ",
"position " : 1 ,
"bytes " : "[73 74] ",
"positionLength " : 1 ,
"termFrequency " : 1
}
]
}
]
}
}
まず、Standard tokenizer によって ["kmc", "test"] といった Token 列に分解される。その後、 N-gram token filter によって各 Token がさらに分解され、最終的に ["km", "mc", "te", "es", "st"] という Token 列が生成されている。
注目すべきは N-gram token filter は分解前の Token の位置情報(position や start,end_offset)を保持している*2 。
イメージとしてはこんなかんじ。
ここで、N-gram token filter で展開された位置情報が同じ Token は Synonym (類義語)として解釈される。
www.elastic.co
その結果、N-gram tokenizer と挙動が異なってくる。
挙動の違いによる影響
インデックスで用いた場合
検索結果
N-gram tokenizer は通常の N-gram として想定したような結果になる。
一方、N-gram token filter の場合、先述したように Synonym としてまとめて解釈されてしまい、細かい位置情報が失われるので phrase 検索がまともに動かない*3 。通常の検索でも、スコアなどの精度が大幅に悪化しそう*4 。
Highlight
Highlight は検索でマッチしたときにマッチした場所を示す用のテキストを抽出し、さらに検索語句に一致する Token に <mark> タグをつけてくれる Elasticsearch の機能。
"のにれん" で検索した結果の Highlight の例。黄色くなっている箇所が mark
N-gram tokenizer であれば実際に一致した箇所のみがハイライトされるが、N-gram token filter の場合は Token filter が Token の位置情報(start, end_offset)を変更しないので、分解前の Token 全体がハイライトされる。
例えば、highlight this というテキストに対して gh で検索したとする。先述の N-gram tokenizer を使うパターンでは gh のみがハイライトされるが、N-gram token filter を使うパターンでは highlight がハイライトされて、やや違和感のある形になる*5 。
github.com
検索クエリで用いた場合
query_string クエリで test や "test" (Phrased) を入れた場合に、最終的にどのようなクエリが実行されるかを見る*6 。
N-gram tokenizer
test: BooleanQuery, body:te body:es body:st
Token それぞれがクエリとなる。OR か AND になるかは default_operator の設定による。
"test": PhraseQuery, body:\"te es st\"
Token に分解された上で、 Phrase 検索が有効になっていることが分かる。test という文字列が存在する場合にのみマッチする。
N-gram token filter
test: SynonymQuery, Synonym(body:es body:st body:te)
Token filter によって分解された Token は Synonym とみなされ、一括で検索になっている。es, st , te のうち一つでも文章に存在すればマッチする。
"test": SynonymQuery, Synonym(body:es body:st body:te)
通常の検索と同じ挙動になっており、Phrase 検索にはなっていない
このように、N-gram Token filter を使うと類義語のようにみなされる結果、SynonymQuery が発行されてしまい、想定と異なる結果(大量の False positive)になってしまう。
まとめ
Elasticsearch の Token filter は元々の Token の位置情報を変更しない、という性質を持つため、N-gram token filter では分解した Token が Synonym として解釈されてしまう。その結果、インデックス時や検索時に意図しない挙動になってしまいやすい。
N-gram tokenizer ではそのようなことがなく、意図した通りの N-gram 処理が行えるのでオススメ。