今年の ISUCON では Elastic Stack を使って MySQL のスローログを Kibana で可視化したが、いくつか課題があった。
パラメーターによってクエリが分散し、ボトルネックが分かりづらい
MySQL スローログは生のクエリが記載されていて、Filebeat の MySQL モジュールはそのまま送信するため、 SELECT クエリなどパラメーターが分散しがちなデータはうまく集計することができず上位に現れづらかった。

Elasticsearch に入れる前に何らかの方法でパラメータを取り除いておきたい。
ログエントリが多い
スロークエリの設定によっては大量のクエリが記録され、その結果大量の(かつ大きな)エントリを Filebeat で処理して Elasticsearch に登録することになる。Filebeat の負荷が厳しくなってアプリのパフォーマンスに影響が出るほか、Kibana ダッシュボードももっさりしてしまう。
全てのスロークエリをそのまま入れて毎回 Elasticsearch で計算を行うのではなく、ある程度まとめた結果を投稿するようにしたい。データの前処理ってやつ。
これを解決するために、スローログを pt-query-digest で定期的に解析し、その結果を Filebeat 経由で Elasticsearch に投入するようにすることで、 Kibana でリアルタイムにまとめて見れるようにした。
pt-query-digest を使おう
pt-query-digest は言わずと知れたクエリログの解析プログラムで、各種パラメーターを取り除いていい感じに抽象化し、それを集計して重いクエリを出してくれる。
デフォルトだとヒューマンリーダブルな結果が出力されるが、 --output オプションを変更すると json で出力することができる。Filebeat は json をパースして内容をフィールドに変換してくれる機能がある *1 ので、 json で出力できればパースの手間をずいぶん抑えることができる。
また、pt-query-digest には --iterations というオプションがあり、標準入力を継続的に読み取って定期実行することができる。
この機能を使って、スローログの内容を継続的に読み取って、 pt-query-digest の集計結果を毎分 json で出せるようにした。
$ sudo tail -F -n +1 /var/log/mysql/mysql-slow.log | pt-query-digest --output=json --iterations=0 --run-time=1m
Filebeat との相性問題
Filebeat に出力された json を直接読みとらせるとエントリとして登録はされるが、そのままだとまだ問題がある。
pt-query-digest の結果は一つの json の中に複数のクエリの情報が入っており、下のような構成になっている。
{ "classes": [ {slow query info}, {slow query info}, ... ], "global": { command info } }
詳細例: pt-query-digestを使用したクエリログの変換について | スマートスタイル TECH BLOG
ここで、Filebeat の ndjson input は 1 行を 1 エントリとして読み込んでしまうので、コマンド結果ごと・複数クエリを内包したエントリになってしまう。それでは解析もやりずらい。
エントリをクエリごとにするには Filebeat だけでは達成できず*2、Elastic Stack 内で済ます場合は Logstash を追加で使う必要がある。Logstash はヘビーなアプリケーションで大変なので、 今回は jq を使って Filebeat に流す前に array を各行に Flatten する。
$ sudo tail -F -n +1 /var/log/mysql/mysql-slow.log | pt-query-digest --output=json --iterations=0 --run-time=1m | jq -R -c --unbuffered 'fromjson | .classes[]' 2>/dev/null {"attribute":"fingerprint","checksum":"E3341326DCBBC41D81C9550FEAE6F248","distillate":"SELECT user_present_all_received_history","example":{"Query_time":"0.100072","query":"SELECT * FROM user_present_all_received_history WHERE user_id=1662038388045 AND present_all_id IN (1, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28)","ts":"2022-09-01T14:02:35"},"fingerprint":"select * from user_present_all_received_history where user_id=? and present_all_id in(?+)","histograms":{"Query_time":[0,0,0,0,27,1,0,0]},"metrics":{"Lock_time":{"avg":"0.000001","max":"0.000006","median":"0.000001","min":"0.000000","pct":"0.070352","pct_95":"0.000001","stddev":"0.000001","sum":"0.000026"},"Query_length":{"avg":"196","max":"198","median":"192","min":"195","pct":"0","pct_95":"192","stddev":"0","sum":"5508"},"Query_time":{"avg":"0.080501","max":"0.100072","median":"0.078474","min":"0.073565","pct":"0.070352","pct_95":"0.090844","stddev":"0.005999","sum":"2.254020"},"Rows_examined":{"avg":"241698","max":"241773","median":"239140","min":"241638","pct":"0","pct_95":"239140","stddev":"0","sum":"6767570"},"Rows_sent":{"avg":"10","max":"27","median":"0","min":"0","pct":"0","pct_95":"26","stddev":"11","sum":"285"},"db":{"value":"isucon"},"host":{"value":"isucon5"},"user":{"value":"isucon"}},"query_count":28,"tables":[{"create":"SHOW CREATE TABLE `isucon`.`user_present_all_received_history`\\G","status":"SHOW TABLE STATUS FROM `isucon` LIKE 'user_present_all_received_history'\\G"}],"ts_max":"2022-09-01T14:13:51","ts_min":"2022-09-01T14:02:35"} ...
-R と 'fromjson' を使っているのは、時折流れてくる非 json なログがあっても処理を続行するため。
フィールドの型問題
これに Filebeat の ndjson input を使うことで各クエリの情報が Elasticsearch に毎分登録されていくようになったが、 pt-query-digest で出力される数値が json では string になっているため、 Elasticsearch では keyword として登録されてしまうという問題があった。keyword として登録されてしまうと数値として扱えず sum や count, top N ができない。
これに関しては、 Filebeat の convert processor を使って特定のフィールドを数値に変換するようにした。その他細々とした調整をして、最終的に filebeat.yaml では以下のような設定になった。
- type: filestream id: mysql-digest-jq paths: - /var/log/mysql-digest-jq.log parsers: - ndjson: target: "mysql-digest" add_error_key: true message_key: "fingerprint" processors: - add_fields: target: 'event' fields: dataset: "mysql-digest" - convert: fields: - from: 'mysql-digest.metrics.Query_time.avg' type: 'float' # 一度登録したフィールドの type は変わらないので、すでに登録してしまっていたら to で新しいフィールドを指定する - from: 'mysql-digest.metrics.Query_time.max' type: 'float' # その他使うフィールドを変換する - timestamp: field: 'mysql-digest.ts_max' layouts: - '2006-01-02T15:04:05' timezone: 'Local'
CPU 大量消費問題
下のような Systemd service を作成して、ISUCON の走っているインスタンスで使ってみた。
[Unit]
Description=pt-query-digest json dumper
[Service]
Type=simple
ExecStartPre=/usr/sbin/logrotate -f /etc/logrotate.conf
ExecStart=/bin/bash -c "tail -F -n +1 /var/log/mysql/mysql-slow.log | pt-query-digest --output=json --iterations=0 --run-time=1m | jq -R -c --unbuffered 'fromjson | .classes[]' >> /var/log/mysql-digest-jq.log"
Restart=always
[Install]
WantedBy=multi-user.target
みんな大好き bash -c 。これで動きはしたが、ベンチを回している途中に pt-query-digest がガンガン回って CPU を1コア食ってしまうようになった。
その対策としては、 CPUWeight をかなり低く設定し、ベンチ中は MySQL に優先して CPU 資源を使わせるようにした*3。
ダッシュボード作成
十分に正規化されたデータを Elasticsearch に入れることができれば、あとはこっちのもの。

Kibana でクエリのいい感じの集約もできて、本当にネックとなっている重いクエリが簡単に分かるようになった。 イベントの量もかなり減って Filebeat のリソース消費で困ることはなくなった。
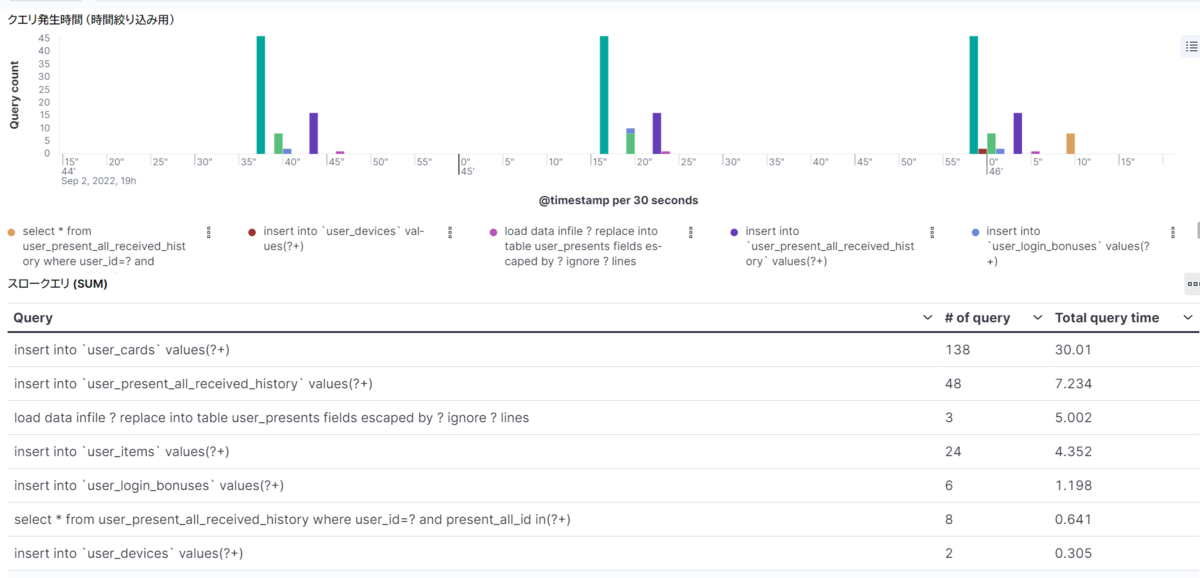
めでたし。
*1:https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-input-filestream.html#_ndjson
*2:1つのエントリ内の array を複数のエントリに分割することは Filebeat ではできない(多分)ので
*3:ちなみに Nice は全然効果なかった